Elasticsearch篇之集群调优建议
系统设置要到位
- 遵照官方建议设置所有的系统参数
- 参见文档 “Setup Elasticsearch -> Importtant System Configuration”
ES设置尽量简洁
- elasticsearch.yml 中尽量只写必备的参数, 其他可以通过api动态设置的参数都通过api来设定
- 参加文档 “Setup Elasticsearch -> Importtant Elasticsearch Configuration”
- 随着ES的版本升级, 很多网络流传的配置参数已经不再支持, 因此不要随便复制别人的集群配置参数
elasticsearch.yml 中建议设定的基本参数
静态参数
- cluster.name
- node.name
- node.master/node.data/node.ingest
- network.host建议显示指定为内网ip, 不要设置为0.0.0.0
- discovery.zen.ping.unicast.hosts 设定集群其他节点地址
- path.data/path.log
- 处上述参数外再根据需要增加其他的静态配置参数
动态参数
- 动态设定的参数有transient和persistent两种设置, 前者在集群重启后会丢失, 后者不会, 但两种设定都会覆盖elasticsearch.yml 中的配置

关于JVM内存设定
不要超过31GB
预留一半内存给操作系统, 用来做文件缓存
具体大小根据该node要存储的数据量来估算, 为了保证性能, 在内存和数据量间有一个建议的比例
- 搜索类项目的比例建议在1:16以内
- 日志类项目的比例建议在1:48~1:96
假设总数据量大小为1TB, 3个node, 1个副本, 那么每个node要存储的数据量为2TB/3=666GB, 即700GB左右, 做20%的预留空间, 每个node要存储大约850GB的数据
- 如果是搜索类项目, 每个node内存大小为850GB/16=53GB, 大于31GB. 31 * 16 = 496, 即每个node最多储存496GB数据, 所以需要至少5个node
- 如果是日志类型项目, 每个node内存大小为850/48 = 18GB, 因此3个节点足够
ES写性能优化
- refresh
- translog
- flush
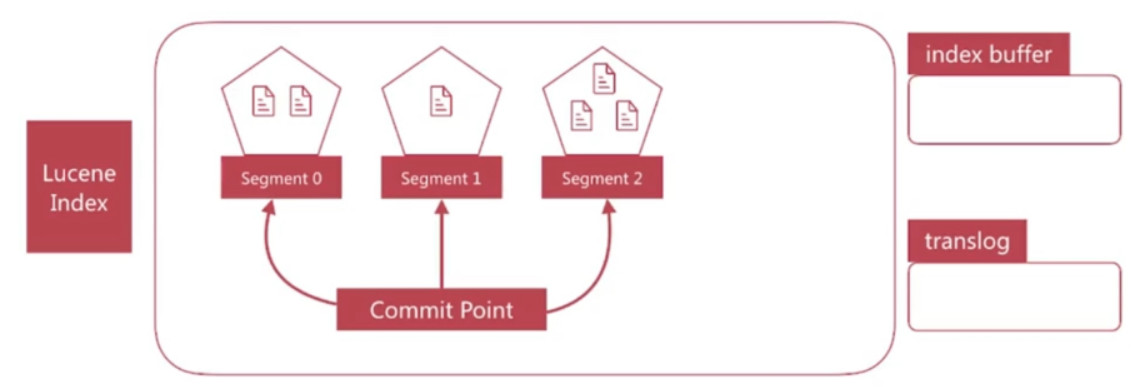
ES写数据 - refresh
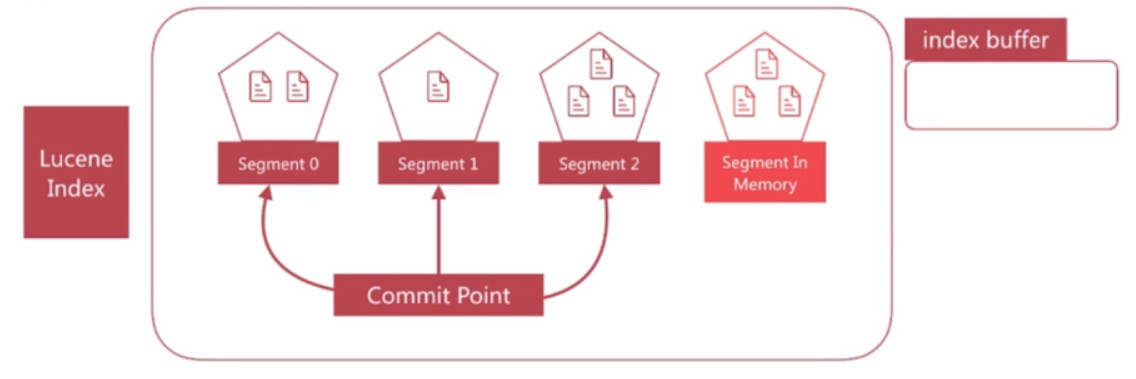
- segment写入磁盘的过程依然很耗时, 可以借助文件系统缓存的特性, 先将segment在缓存中创建并开放查询来进一步提升实时性, 该过程在es中称为refresh
- 在refresh之前文档会先存储在一个buffer中, refresh时将buffer中的所有文档清空并生成segment
- es默认每一秒执行一次refresh, 因此文档的实时性被提高到1秒, 这也是es被称为近实时(Near Real Time)的原因
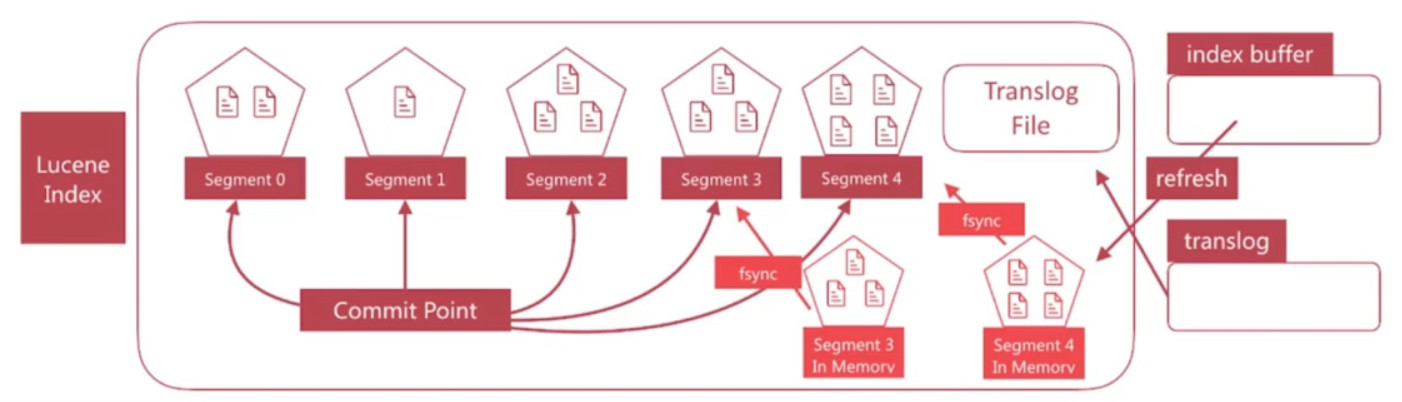
ES写数据 - translog
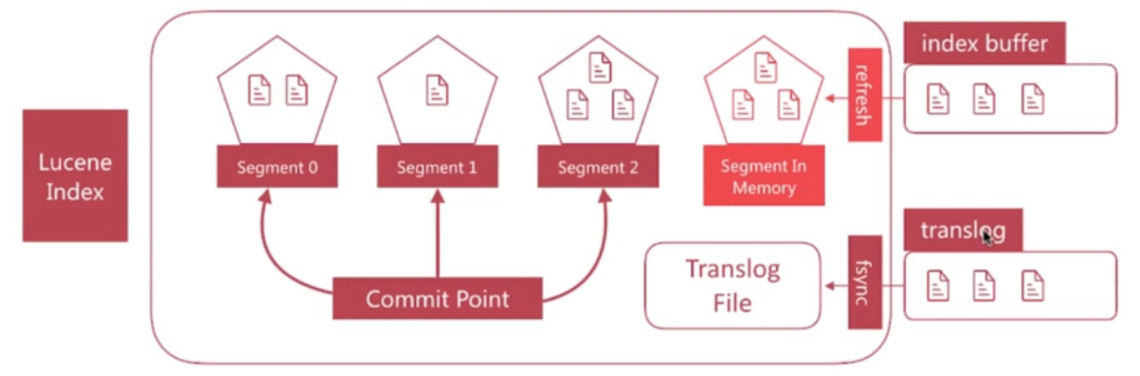
- 如果在内存中的segment还没有写入磁盘前发生了宕机, 那么其中的文档就无法恢复了, 如何解决这个问题?
- es引入了translog机制, 写入文档到buffer时, 同时将该操作写入translog.
- translog文件会即时写入磁盘(fsync), 6.x 默认每个请求都会落盘, 可以修改为每5秒写一次, 这样风险便是丢失5秒的数据, 相关配置为index.translog.*
- es启动时会检查translog文件, 并从中恢复数据
ES写数据 - flush
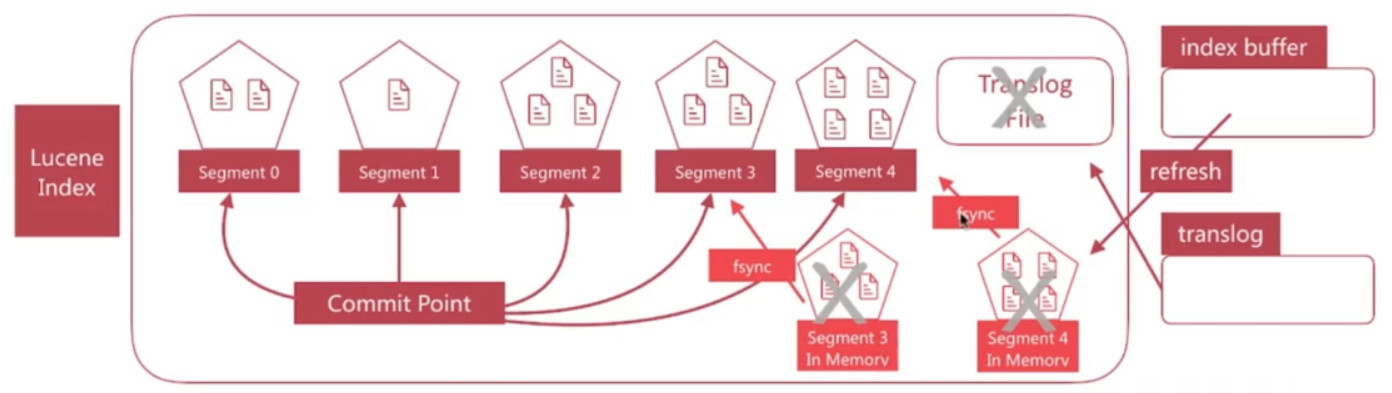
- flush负责将内存中的segment写入磁盘, 主要做如下的工作:
- 将translog写入磁盘
- 将index buffer清空, 其中的一个文档生成一个新的segment, 相当于一个refresh操作
- 更新commit point并写入磁盘
- 执行fsync操作, 将内存中的segment写入磁盘
- 删除旧的translog文件
写性能优化
- 目标是增大写吞吐量 - EPS (Event Per Second)越高越好
- 优化方案
- 客户端: 多线程写, 批量写
- ES: 在高质量数据建模的前提下, 主要是在refresh, translog 和 flush之间做文章
写性能优化 - refresh
- 目标为降低refresh的频率
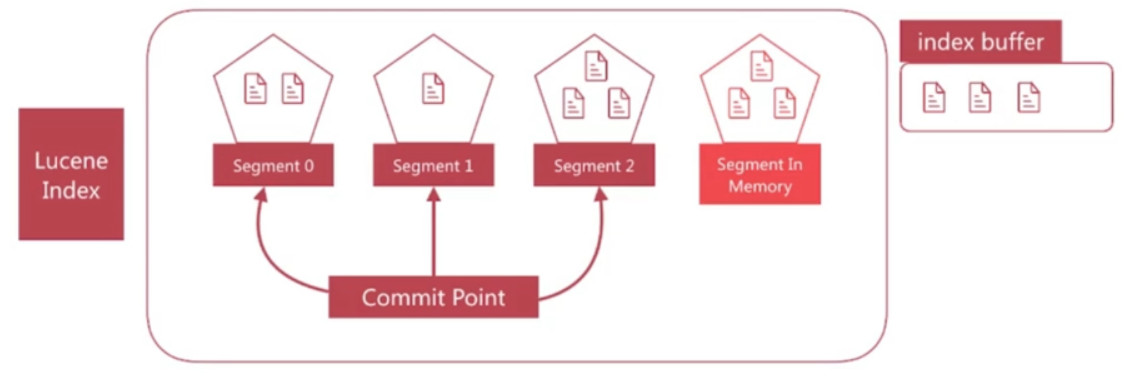
- 增大refresh_interval, 降低实时性, 以增大一次refresh处理的文档数, 默认是1s, 设置为-1直接禁止自动refresh
- 增大index buffer size, 参数为indices.memory.index_buffer_size (静态参数, 需要设定在elasticsearch.yml中), 默认是10%
写性能优化 - translog
- 目标是降低translog写磁盘的频率, 从而提高写效率, 但会减低容灾能力
- index.translog.durability设置为async, index.translog.sync_interval设置需要的大小, 比如120s, 那么translog会改写为每120s写一次磁盘
- index.translog.flush_threshold_size默认为512MB, 即translog超过该大小时会触发一次flush, 那么调大该大小可以避免flush的发生
写性能优化 - flush
- 目标为降低flush的次数, 在6.x可优化的点不多, 多为es自动完成
写性能优化 - 其他
副本设置为0, 写入完毕再增加
合理的设计shard数, 并保证shard均匀的分配在所有的node上, 充分利用所有node的资源
- index.routing.allocation.total_shards_per_node限定每个索引在每个node上可分配的总主副分片数
- 5个node, 某索引有10个主分片, 1个副本, 上述值应该设置为多少?
- (10 + 10)/5 = 4
- 实际要设置5个, 防止某个node下线时, 分片迁移失败的问题
写性能优化主要为index级别的设置优化, 以日志为场景, 一般会有如下的索引设定

读性能优化
- 读性能主要受以下几方面影响:
- 数据模型是否符合业务模型?
- 数据规模是否过大?
- 索引配置是否优化?
- 查询语句是否优化?
读性能优化 - 数据建模
- 高质量的数据建模是优化的基础
- 将需要通过script脚本动态计算的值提前算好作为字段存到文档中
- 尽量使用数据模型贴近业务模型
读性能优化 - 数据规模
- 根据不同的数据规模设定不同的SLA
- 上万条数据与上千万条数据性能肯定存在差异
读性能优化 - 索引配置调优
- 索引配置优化主要包括如下:
- 根据数据规模设置合理的主分片数, 可以通过测试得到最合适的分片数
- 设置合理的副本数目, 不是越多越好
读性能优化 - 查询语句调优
- 查询语句调优主要有以下几种常见手段
- 尽量使用Filter上下文, 减少算分场景, 由于Filter有缓存限制, 可以极大提升查询性能
- 尽量不使用Script进行字段计算或者算分排序
- 结合profile, explain API分析慢查询语句的症结所在, 然后再去优化数据模型
读性能优化
- 没有万金油, 都要靠实战出真知
如何设定Shard数


X-Pack
X-Pack作为一组闭源特性,扩展了弹性堆栈——也就是Elasticsearch、Kibana、Beats和Logstash的监控等功能。




